Mirror Tumblr Picture Blogs with Browsr 07 March 2014
Browsr is a simple demo application I built as a learning exercise over the period of a few weekends.
While a lot of the features are only just functional enough to consider them as having been implemented, I was still quite happy with how it turned out, and the amount of practical experience I gained was quite significant.
Since I don’t really have the time to commit to maintaining the app, I was originally going to keep it to myself until I realized it would be a good thing to add to my online portfolio.

Main Features
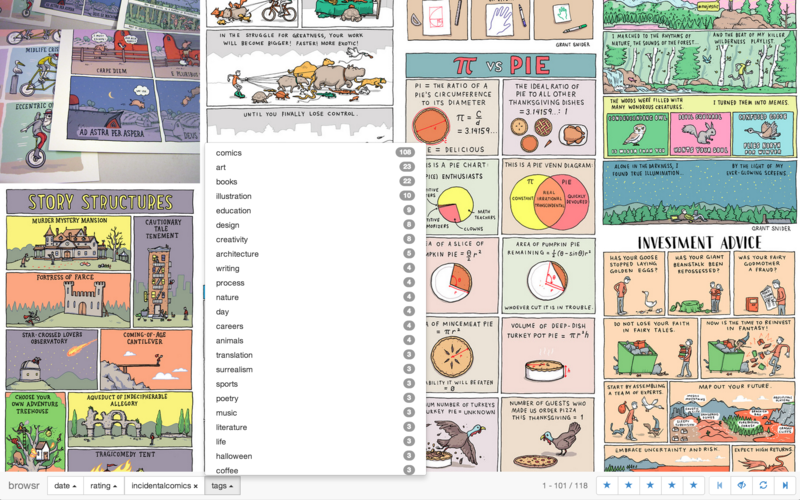
- Downloads and mirrors the photos on tumblr blogs locally.
- Provides a photo mosaic interface to navigate through them.
- Rate images 1-5 stars to keep track of your favorites.
- Allow faceted search on metadata (such as tags).
- Infinite scrolling or paged view modes.
- Keep track of images you have seen, only showing new ones.
- Rudimentary tablet support.

Architecture
Since I built this primarily to learn new technologies, I really crammed as many new things that I could legitimately make use of. I’ve compiled a list of some of the more notable items below.
Primary components
- Angular based front end.
- CouchApp to host the UI.
- CouchDB database, with all images as attachments.
- Elasticsearch used to index and query the data. (Indexes the couch documents via the couchdb river).
- Node.js based proxy, that mostly is a straight pass-through to ES/Couch.
- node.io based scraping back-end, allowing multi-threaded mirroring of sites.
Additional Tools
- Yeoman used for the couchapp generator.
- Bower used for client-side dependencies, as I’m usually a browserify guy.
- Grunt used for complex build processes.
- Masonry based cascading grid layout.
- ngInfiniteScroll for infinite scrolling.
Motivation
I was using this Tumblr Collage chrome extension, but I found it became too unstable on any relatively large site. The way that it relied on localStorage, and it’s single page design, meant that it would also never be able to cleanly track where you were in a large gallery.
The only existing mirroring tools I could find were some once-off ruby scripts that had a chain of out-of-date dependencies, and none of those would get me any closer to having the kind of user interface I wanted. Since I’ve also been largely unhappy with desktop image browsers, just getting the files on my disk wasn’t really going to get me any closer either.
After thinking about the problem a bit I realized it was an ideal space to play with a growing list of libraries and techniques that had been on my radar for a while, but I had never been able to find the right outlet for.
Lessons learned
Many of the the tools I was experimenting with have become parts of my arsenal, and quite a few of them I would happily use again if presented with the right kind of problem.
The process of cleaning this up a bit for public consumption actually resulted in one of the more important lessons I learned, as I was suddenly faced with having to provide a general way of migrating the records stored in the CouchDB database to newer versions of the schema.
This rather fundamental requirement was something I had somehow managed to avoid for the last few years by mostly working on single instances that could be easily updated with once-off scripts.
The solution I built is out of scope for this article, but it’s definitely something I am going to write more about in the future.