JSON Schema and CouchDB bulk import performance 15 May 2012
This project launched successfully, check out the release announcement for more info.
I have revised and double checked this article before publishing, but I am able to re-run the benchmarks.
During the last week I have been responsible for fixing a number of critical issues on the FEBP project to get it ready for the client to be able to work with it. One of the areas I ended up needing to spend a lot of time on was improving performance related to data import and validation.
Background
On the FEBP site, the administrator is able to upload a CSV file describing the data for each of the data sets, which then changes how we interpret and display this data, and they can upload new versions of the data itself. Each dataset and schema is versioned, and the site has the concept of an “active version”.
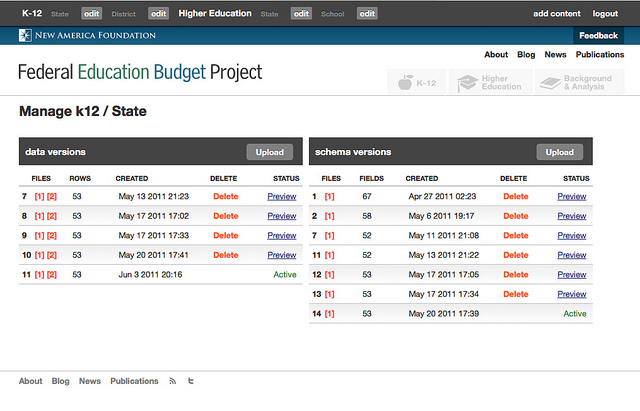
When the admin uploads a new version of the data, once it is imported they are required to validate it against a schema, and are able to preview the new combination of data/schema. If they are happy with the results, and the data / schema have been validated successfully, they are able to set this new combination active, which changes what is published on the site. So you have a situation where you have multiple versions of large datasets being accessed at the same time.
Our problem was that we were running into issues that only occurred late in the import process in these large records, and which were fairly difficult to reproduce or debug.
Validation speed
The first problem I tackled , was the fact that validating the larger datasets (13 000+ records), the process was not only taking hours, but was also actually completely blocking and was making the site completely unavailable, until it was complete or the process died.
After getting to the point of even attempting to partially rewrite JSV to turn it into an asynchronous library, I discovered that the recommended and documented usage of the library, by invoking the env.validate method, was not just validating our data as we’d wanted, but was actually validating our schema again too.
Because JSON-schema is self hosted, this meant that for each object we wanted to validate, it was parsing and building an object representation of the json schema spec itself, to be able to build an object representation of our schema and validate that against the base spec, and then it would only get to do the validation we asked it to do.
Using a cached schema object
The solution ended up being generating a schema object at the start of the batch, and then storing a reference to it, so we could re-use it.
- var report = env.validate(record.doc, { $ref: 'urn:' + that.section + '#'});
+ var report = that.schema.validate(record.doc);You can generate the schema object by doing the following. The last parameter is important, because it allows you to reference the schema in other schemas.
var schema = env.createSchema({
'type': 'object',
'patternProperties': {
'^[0-9]{4}$': {
'type': ['string', 'null']
}
}
}, undefined, 'urn:seriesYear#');After that 1 line fix, that took 6 hours to track down, the performance improved to the point where there is no effect on the response time of the site, and it takes less than 20ms to validate each record, down from a glacial and blocking 200ms per record.
Import speed
The next issue I tackled was related to the behavior of the user interface while importing large datasets. This was a bit of a problem for me, because for reasons I have still not been able to fully determine, my laptop takes far far far longer to run our data bootstrapping and import scripts than the other developers on the projects. Running kick.sh has gotten to a point where it takes at least an hour to import all the data, whereas Jeff and the rest reported times of about 15 minutes.
To be able to test this at all, I needed to not only improve the speed, but also have more information to work with. As i’d discovered with the validation, none of the nifty profiling tools available for node work on 0.2.x, I started adding the timers and debug statements to the code. This allowed me to see more clearly how long tasks were taking.
Sequential ID’s
After doing a lot of reading, I came upon this nice piece of information, on the couchdb wiki :
The db file size is derived from your document and view sizes but also on a multiple of your _id sizes. Not only is the _id present in the document but it and parts of it are duplicated in the binary tree structure CouchDB uses to navigate the file to find the document in the first place. As a real world example for one user switching from 16 byte ids to 4 byte ids made a database go from 21GB to 4GB with 10 million documents (the raw JSON text when from 2.5GB to 2GB).
Inserting with sequential (and at least sorted) ids is faster than random ids. Consequently you should consider generating ids yourself, allocating them sequentially and using an encoding scheme that consumes fewer bytes. For example something that takes 16 hex digits to represent can be done in 4 base 62 digits (10 numerals, 26 lower case, 26 upper case).
What happens is that if you have random id’s, couchdb has to filter through all the other records in order to sort them correctly, when the ID’s are sequential, it can just keep on adding them to the end of where it inserted last time. With some pretty minor changes, I was able to generate unique numeric identifiers, and then using the Number.prototype.toString() method, turn it into a very densely compacted string, which sped up my imports significantly.
with sequential ids:
Done: imported 13642 rows into k12_district as version 1 in 674990ms. Average: 49ms per record. # 11.25 minutes
Done: imported 7523 rows into higher_ed as version 1 in 718131ms. Average: 95ms per record. # 12 minutes
View generation is painfully slow.
In order to allow us to have a usable site while imports are taking place, we chose the procedure of importing 100 records at a time, and then hitting the views to force them to regenerate in smaller increments. Almost all of our views are actually very simple and reasonable, save for one:
Rebuilt _design/counts in 326ms.
Rebuilt _design/data in 495ms.
Rebuilt _design/districts in 22658ms. # that is 22 seconds for you and me
Rebuilt _design/schema in 22893ms.
Imported rows 13501 to 13600 into k12_district in 23260ms. Average: 48ms per record.
What is happening in that slow view, is that it is having to iterate over each of the records, over each of their properties and then emit’ing a record indexed by the data version, the property name and the value for that property. In the case of yearly indicators, it also has to go and find the most recent value of that indicator to emit. With a single version of the k12_district data, that amounts to 579059 items in the byIndicator view, which multiplies with each additional version, taking longer and longer and longer to build every time.
I’ve decided to split this post here, to not bury the lead. Check out my next devlog to see what i used to solve this.