Elasticsearch - 5 minute search integration 01 May 2012
I have refactored the example code and made it less client specfic, and supporting the latest versions of node and ES.
One of the lingering tickets on the FEBP project is building full text search for the documents database, and this is the simplest way I have discovered to implement something like this.
Elastisearch is to Solr what CouchDB is to MySQL. It is marvelously simple to get going. You download a file, run a command and then you can index JSON with it via Curl.
Another great thing is that every time it starts up it seems to give itself a new name. The first time I played with it, it dubbed itself Algrim the Strong. It’s not often I run across software that makes me smile just from using it.
The 5 minute tour
The real killer feature is their integration with CouchDB. With a few simple commands you will not only be indexing a CouchDB database, but it will subscribe to it’s _changes feed, meaning that it keeps itself up to date the whole time, without you needing to do a damn thing about it.
- Download and extract the binaries
- install the couchdb river plugin
bin/plugin -install elasticsearch/elasticsearch-river-couchdb/1.1.0
-> Installing elasticsearch/elasticsearch-river-couchdb/1.1.0...
Trying https://github.com/downloads/elasticsearch/elasticsearch-river-couchdb/elasticsearch-river-couchdb-1.1.0.zip...
Downloading ............DONE
Installed river-couchdb- start the service
bin/elasticsearch- create the river
curl -XPUT 'http://localhost:9200/_river/documents_idx/_meta' -d '{
> "type" : "couchdb",
> "couchdb" : {
> "host" : "localhost",
> "port" : 5984,
> "db" : "febp_documents",
> "filter" : null
> }
> }'
{"ok":true,"_index":"_river","_type":"documents_idx","_id":"_meta","_version":1}- You now have a working automagic couch index web service, query it to check :
curl 'http://localhost:9200/febp_documents/_search?q=about&pretty=true&size=1'
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 29,
"max_score" : 0.07392572,
"hits" : [ {
"_index" : "febp_documents",
"_type" : "febp_documents",
"_id" : "background-analysis",
"_score" : 0.07392572, "_source" : { /* snipped for the example */ }
} ]
}
}-
Less than 100 lines of express + jade later, you have basic search functionality. see the code
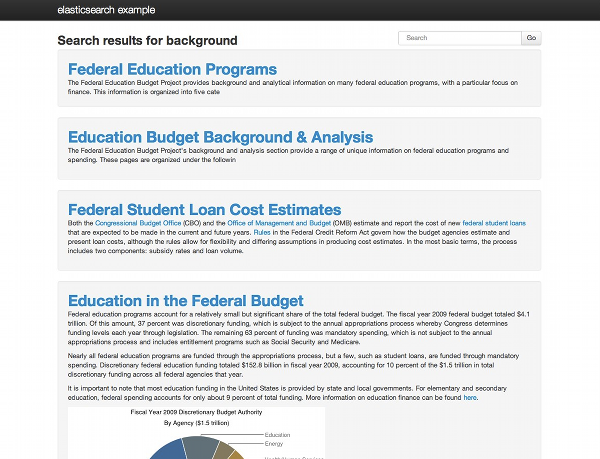
The Tip of the Iceberg
Obviously it can do more, but I have really not taken the time to play further than this. I know it has some form of geo-spatial support, and it is also very easily clustered. It has more than just plain text search, as it indexes JSON and you can even do property lookups and so forth.